
Automatic Word Clustering: K-Means Clustering for Words
K-Means clustering is a popular technique to find clusters of data based only on the data itself. This is most commonly applied to data that you can somehow describe as a series of numbers.

When you can describe the data points as a series of numbers, K-Means clustering (Lloyd’s Algorithm) takes the following steps:
- Randomly pick a set of group representatives. Lloyd’s algorithm generally picks random coordinates, although sometimes picks specific random data points.
- Assign all of the items to the nearest representative.
- Update the group representative to more accurately represent its members. In Lloyd’s algorithm, this means updating the location of the representative to represent the average location of every item assigned to it.
- Revisit all of the items, assigning them to their nearest group representative.
- If any items shifted groups, repeat steps 3-5.
Applying this technique directly to words is not possible, as words don’t have coordinates. Because of that:
- Randomly picking a coordinate cannot be used to randomly create a group representative.
- Refining a group representative based on its current word cluster is more complicated than simply averaging the coordinates of the items in the cluster.
If we follow the philosophy of Lloyd’s algorithm, however, we can still create a version of K-Means Clustering for Words. In our implementation, we:
- Pick random words from the provided list as group representatives.
- Use Levenshtein Distance (string similarity) to measure “nearest group representative”.
- Use word averaging to update the nearest group representative. Word averaging is a new word of the “average” word length, with characters at each position created by taking the most common letter at that position.
This is very computationally expensive for large data sets, but can provide some very reasonable clustering for small data sets.
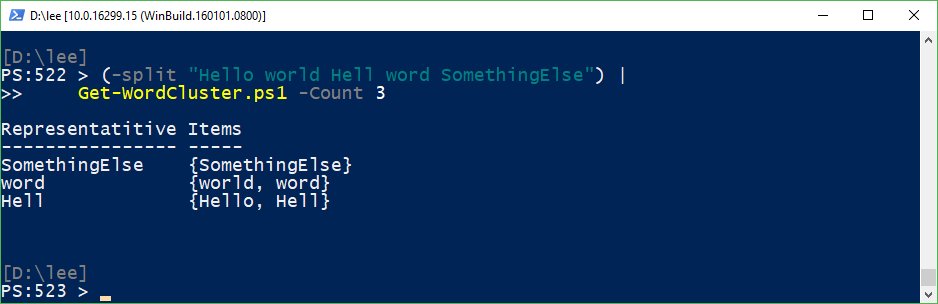
To explore this further, you can download Get-WordCluster from the PowerShell Gallery. It’s as simple as:
- Install-Script Get-WordCluster –Scope CurrentUser
- (-split “Hello world Hell word SomethingElse”) | Get-WordCluster -Count 3